看下巴就够?识别无声语言的项链来了

想象一下,如果你坐在落针可闻的会议室或图书馆,脱口而出「Siri,看看明天的天气」,这或许并不合适。
当一个人说不了话或者必须保持安静,却需要给智能设备指令,这该怎么办?
为此,康奈尔大学的信息科学助理教授 Cheng Zhang 和博士生 Ruidong Zhang,设计了一款叫做 「Speechin」的项链。

▲ 图片来自:Cornell University
它基于下巴运动,捕捉「颈部和面部皮肤变形图像」,从而识别无声语言,目前可以识别英语和中文的简单短语。
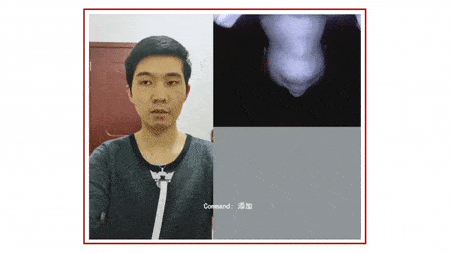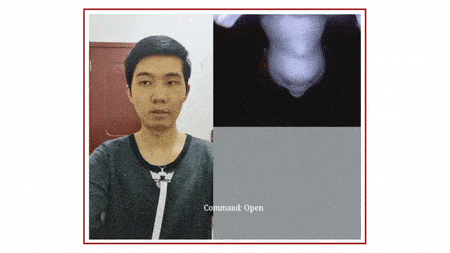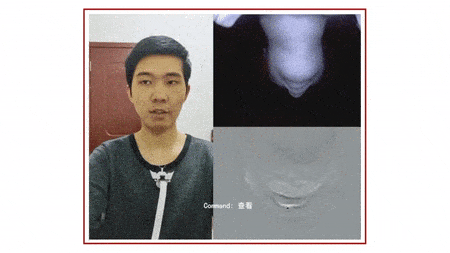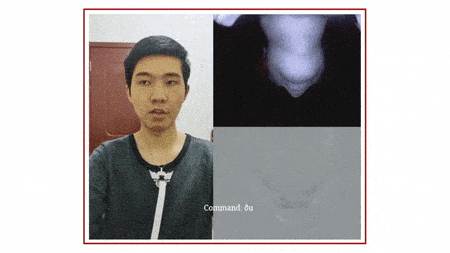
▲ 动图制作自:YouTube@Cornell University
SpeeChin 的红外摄像头安装在 3D 打印的「项链盒」上,「项链盒」挂在银链上,摄像头指向佩戴者的下巴。为了提高稳定性,开发人员在两侧设计了「机翼」,并在底部放置了一枚硬币。
除了这些,SpeeChin 还配备有微处理器、电池和蓝牙模块。

▲ 图片来自:Cornell University
利用基于机器学习的算法,该设备能根据佩戴者的下巴运动,确定佩戴者在无声地说出哪些命令,然后将这些命令中继到配对的智能手机,就像另一种沟通方式下的 Siri。
为了避免隐私问题,SpeeChin 只会怼向下巴下方,不会直接指向用户的脸。
在最初的试验中,有 20 名参与者(10 名说英语,10 名普通话),研究人员测量了他们下巴的基线位置,然后使用差分图像训练 SpeeChin 识别简单命令。
10 位英语参与者默默说出 54 条命令,包括数字、交互命令、语音助手命令、标点命令和导航命令,其他 10 位普通话参与者的 44 条命令也是如此。
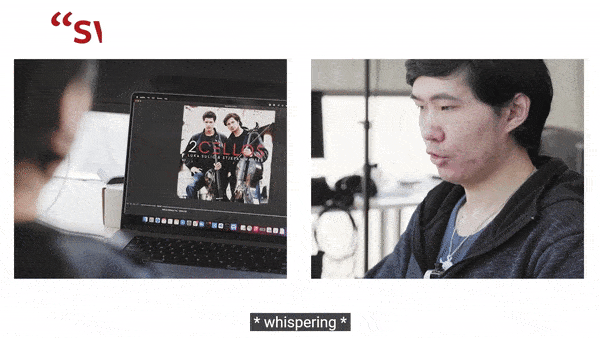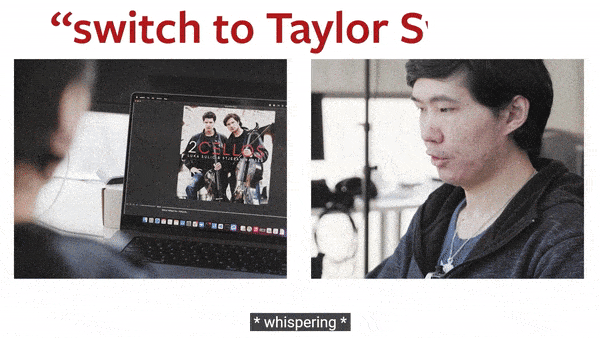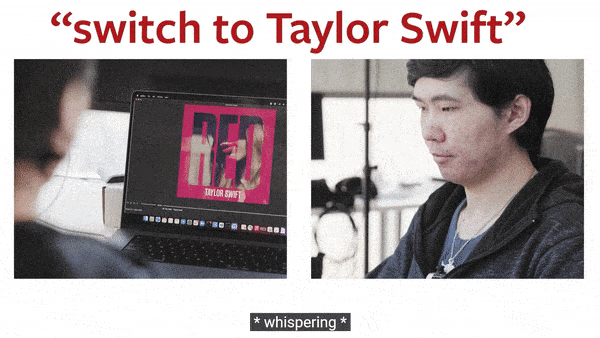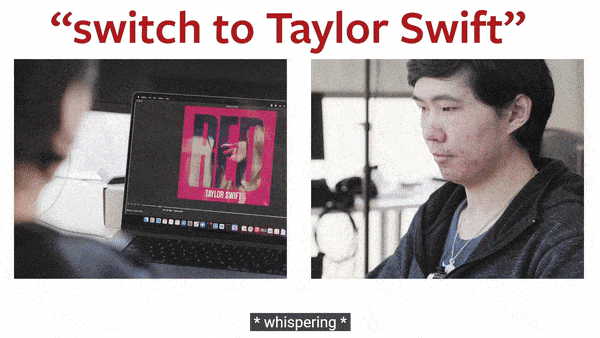
▲ 动图制作自:YouTube@Cornell University
事实证明,SpeeChin 识别英语和普通话命令的平均准确率分别为 90.5% 和 91.6%。研究人员表示,这款设备有可能学习一个人的无声语音模式。
研究人员还要求 6 名参与者在行走时默默说出 10 个普通话和 10 个英语短语。这项研究的成功率较低,主要是因为参与者的头部以不可预测的方式移动。
为什么要以项链的形式做无声语音识别这件事?一位研究人员阐述了他们的研究目的:
我们认为项链是人们习惯的一种形式,而不是耳挂式设备,后者可能不太舒服;至于无声语音,人们可能会想「我的手机上已经有语音识别设备了」。但是你需要为一些无法发声的人和场合发声。
值得一提的是,SpeeChin 在外观上与 NeckFace 相似。NeckFace 是 Cheng Zhang 和他的 SciFi Lab 团队去年推出的设备,通过使用红外摄像机,在颈部下方捕捉下巴和面部的图像,并生成完整表情的 3D 重建,从而持续跟踪面部表情。

▲ 动图制作自:YouTube@CornellScifiLab
NeckFace 在心理健康领域可能特别有用,因为它可以跟踪人们一天中的情绪。虽然人们并不总是把情绪表现在脸上,但随着时间的推移,面部表情的变化量可能表明情绪波动。
NeckFace 也可以用于其他场景,比如在无法选择前置摄像头时进行虚拟会议、虚拟现实场景中的面部表情检测等等。
如果 SpeeChin 进一步发展,它的使用场景同样会越来越多,包括必须静音的环境、无法识别的嘈杂环境以及缺乏语言能力的人群。
葡萄不是唯一的水果。
