突破实时生成瓶颈,Soul CEO张璐团队发布开源模型SoulX-LiveAct
聚焦长时稳定与实时推理,Soul CEO张璐团队开源SoulX-LiveAct模型
近日,Soul App CEO张璐团队宣布,其AI研究团队Soul AI Lab正式发布开源模型SoulX-LiveAct。作为面向实时数字人生成的重要技术成果,该模型围绕“长时稳定”与“实时流式”两大核心目标,对现有生成范式进行了系统性优化。在数字人直播、视频播客以及实时互动场景不断扩展的背景下,SoulX-LiveAct为实时生成技术的工程化落地提供了新的实现路径。
随着人工智能在内容生成领域的应用加速,数字人技术逐渐从实验性演示走向实际应用场景。然而,在长时间运行的情况下,传统生成模型往往难以保持一致表现。当视频生成时长延伸至分钟甚至小时级,模型容易出现身份漂移、细节退化、画面闪烁等问题,同时推理成本也会随时间增加而上升。
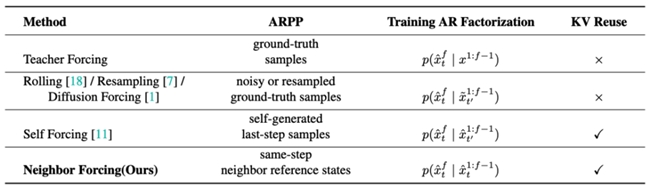
针对上述挑战,SoulX-LiveAct在整体架构上采用自回归扩散(AR Diffusion)范式,并引入Neighbor Forcing与ConvKV Memory两项关键机制,构建面向长时序生成的稳定体系。在具体实现上,模型以chunk为基本生成单元,通过逐段生成与上下文衔接,实现连续的视频输出。在每个chunk内部,扩散模型负责细节建模,而在chunk之间,通过条件信息传递实现动作与身份的一致延续,从而形成完整的流式推理闭环。
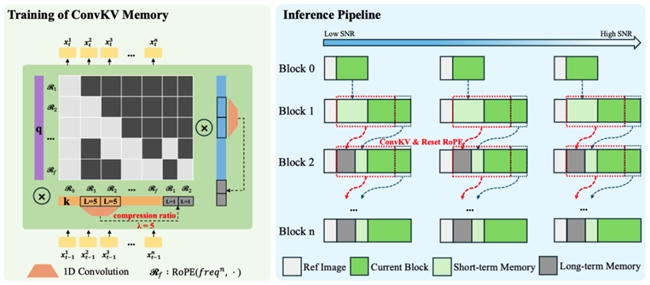
在核心机制方面,Neighbor Forcing通过在同一扩散步内传播相邻帧的latent信息,使模型在统一的噪声语义空间中进行预测,有效降低训练与推理过程中因分布不一致带来的不稳定因素。与此同时,ConvKV Memory对历史信息进行结构性压缩,将传统线性增长的缓存转化为“短期精确+长期压缩”的组合形式:近期信息保留高精度以保证局部细节,远期信息通过轻量卷积进行压缩,从而在控制内存占用的同时保留关键上下文信息。此外,模型还通过RoPE Reset对位置编码进行对齐,进一步减少长序列生成中的位置漂移问题。
在推理效率方面,SoulX-LiveAct强调“稳定延迟”与“恒定显存”。通过ConvKV Memory机制,历史信息不再随时间线性增长,使显存占用保持在固定范围内。这一设计使得模型在长时间运行过程中,计算与通信成本保持稳定,不会随着视频长度增加而显著上升。在实际性能表现上,系统在512×512分辨率下,可在2×H100/H200硬件条件下实现20 FPS的流式推理,同时端到端延迟约为0.94秒,计算成本为27.2 TFLOPs/frame,体现出较为均衡的实时性与资源利用效率。
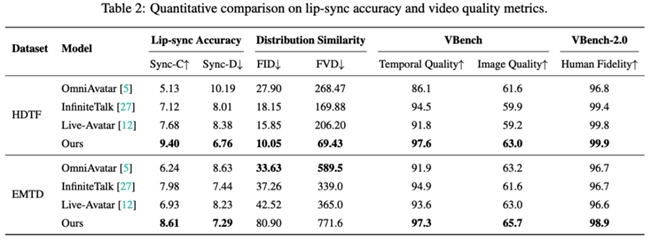
在多项评测基准中,SoulX-LiveAct也展示了其综合性能优势。在HDTF数据集上,模型取得9.40的Sync-C与6.76的Sync-D,在分布相似性指标上达到10.05 FID与69.43 FVD,并在VBench中获得97.6的Temporal Quality与63.0的Image Quality,VBench-2.0的Human Fidelity达到99.9。在EMTD数据集上,模型同样保持领先表现,取得8.61 Sync-C与7.29 Sync-D,并在VBench中实现97.3的Temporal Quality与65.7的Image Quality,Human Fidelity达到98.9。这些结果表明,该模型在口型同步、动作一致性以及整体画面稳定性方面具备较强能力。
基于上述性能表现,SoulX-LiveAct能够支持多种需要长期在线运行的应用场景,包括数字人直播、AI教育、智慧服务终端以及知识内容生产等。在开放世界互动场景中,数字角色需要在长时间交互过程中持续保持一致表达能力。SoulX-LiveAct在全身动作数据集上的表现以及其实时流式推理能力,使其具备支持此类复杂场景的基础条件。
SoulX-LiveAct的发布,也延续了Soul AI团队在实时数字人方向的技术布局。此前,团队已开源SoulX-FlashTalk与SoulX-FlashHead两个模型,分别在超低延迟与轻量化部署方面进行了探索。此外,团队还在语音与交互领域推出了SoulX-Podcast、SoulX-Singer以及SoulX-Duplug等模型与模块,逐步构建围绕“实时交互”的多模态技术体系。
通过持续开放模型与技术方案,Soul CEO张璐团队不仅推动了自身AI能力的迭代,也为开发者社区提供了可复用的技术基础,促进更多应用场景的探索与落地。
